本页目录
运行时
运行时通过 MCP 把编译后的 corpus 提供给 agent,只有一条铁律:
绝不读取 chunk 内容。它只返回 metadata 和投影路径,
原子正文交给 agent 自己的 Read 工具去取。
查询流
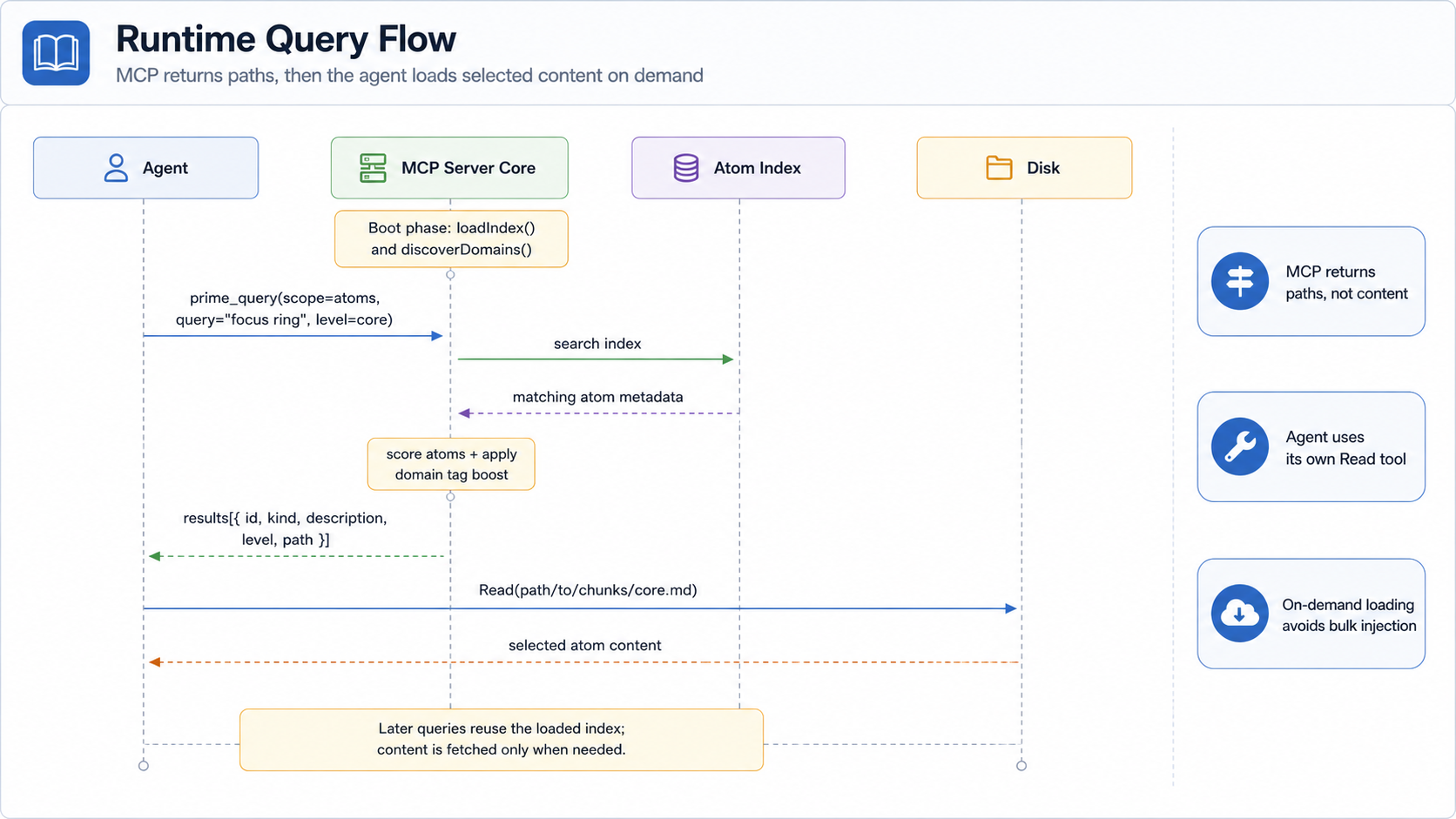
注意:运行时只返回路径,从不返回原子正文。原因有两条:
- agent 已经自带
Read工具,能高效流式读取内容,运行时没必要再做一遍。 - 正文如果留在运行时这一侧,很容易催生服务端缓存,而那会和 agent 自己的上下文预算抢资源。
两个阶段
启动
第一个 MCP 请求触发启动。运行时读取 _index.xml,递归扫描各处的
domain.yaml,把它们注册到进程内的 DomainRegistry,
全程不会读任何 chunks/*.md。
稳态查询
每次 MCP 查询都是一次同步的内存操作:
- 按 6 轴打分(kind / tag / edge / fit / persona / quality)。
- 叠加
domain.yaml中配置的 domain tag boost。 - 解析 contract(must-include / must-avoid / conditional)。
- 在请求预算约束下,为每个原子算出投影层级。
- 返回
{ hits: [{ id, kind, path, tokens, ... }] }。
5 个 MCP 工具
参考实现的 server 对外暴露五个工具,任意 MCP 客户端都能调用:
| 工具 | 用途 |
|---|---|
prime_query | 按 tag / kind / scope / 预算搜索原子。 |
prime_resolve | brief 转成排序后的原子集合(内部依次跑 L1 + L2 + L3)。 |
prime_intent | brief 转成 IntentObject(只跑 L1)。 |
prime_validate | 给定生成产物和原子集合,得出裁决(L5)。 |
prime_compile | 临时编译一份 .prime 源码,便于测试。 |
缓存
Index 解析后的内存图,在 server 进程生命周期内常驻缓存; atom-yaml metadata 在第一次被查询命中时才懒加载; 图查询不做缓存(≤ 10k 原子的规模下足够便宜)。
重载
运行时默认监听 index 文件的 mtime,touch 一下 _index.xml 就会触发 metadata 热更新。
chunk 内容的变化对运行时是不可见的——这是有意为之,只有 agent 真正去读的时候才会看到。