On this page
Runtime
The runtime serves a compiled corpus to agents over MCP. It has one rule:
never read chunk content. The runtime serves metadata and
projection paths. The agent reads atom bodies via its own Read tool.
Query flow
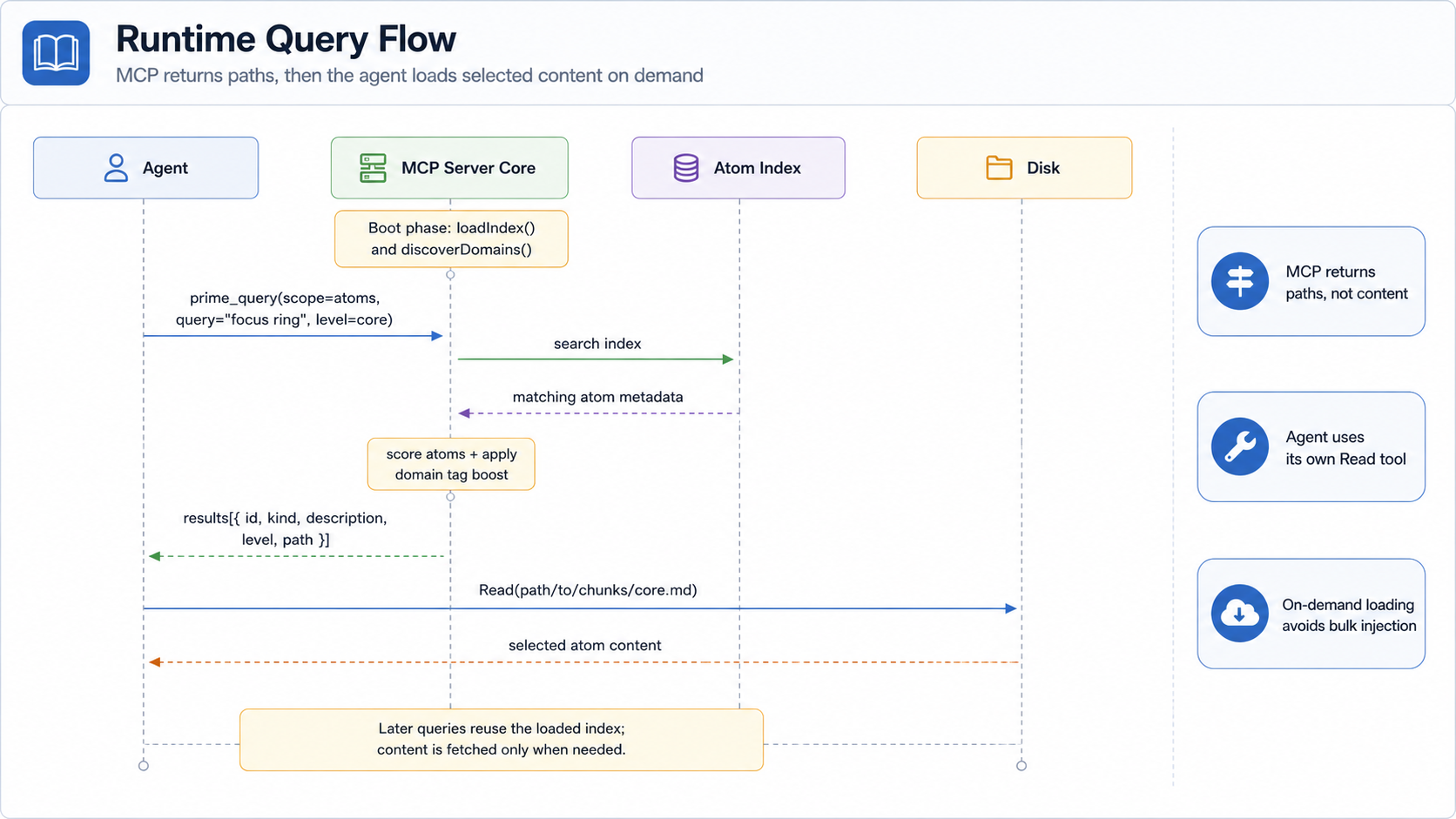
Notice the runtime returns paths — never atom body content. Two reasons:
- The agent's existing
Readtool already streams content efficiently and the runtime should not duplicate that work. - Bodies on the runtime side would tempt server-side caching that competes with the agent's context budget.
Two phases
Boot
First MCP request triggers boot. The runtime reads _index.xml,
discovers domain.yaml files recursively, and registers them with the
in-process DomainRegistry. It does not read any
chunks/*.md.
Steady-state queries
Each MCP query is a synchronous in-memory operation:
- Score candidates by 6-axis ranking (kind / tag / edge / fit / persona / quality).
- Apply domain tag boost from
domain.yaml. - Resolve contracts (must-include / must-avoid / conditional).
- Compute projection level for each atom under the requested budget.
- Return
{ hits: [{ id, kind, path, tokens, ... }] }.
5 MCP tools
The reference server exposes five tools to any MCP client:
| Tool | Purpose |
|---|---|
prime_query | Search atoms by tag / kind / scope / budget. |
prime_resolve | Brief → ranked atoms (calls L1 + L2 + L3 internally). |
prime_intent | Brief → IntentObject (L1 only). |
prime_validate | Generated artifact + atom set → verdict (L5). |
prime_compile | Compile a .prime source on the fly (testing). |
See MCP tool schemas for full input/output JSON-Schema.
Caching
Index parse → in-memory graph: cached for the lifetime of the server process. Atom-yaml metadata: cached lazily as queries reference each atom. Graph queries: not cached (cheap enough at corpus sizes ≤ 10k atoms).
Reload
The runtime watches the index file's mtime by default; touching
_index.xml triggers a hot reload of metadata. Chunk-content changes
are invisible to the runtime by design — only the agent sees them when it reads.