On this page
Projection · 3 levels
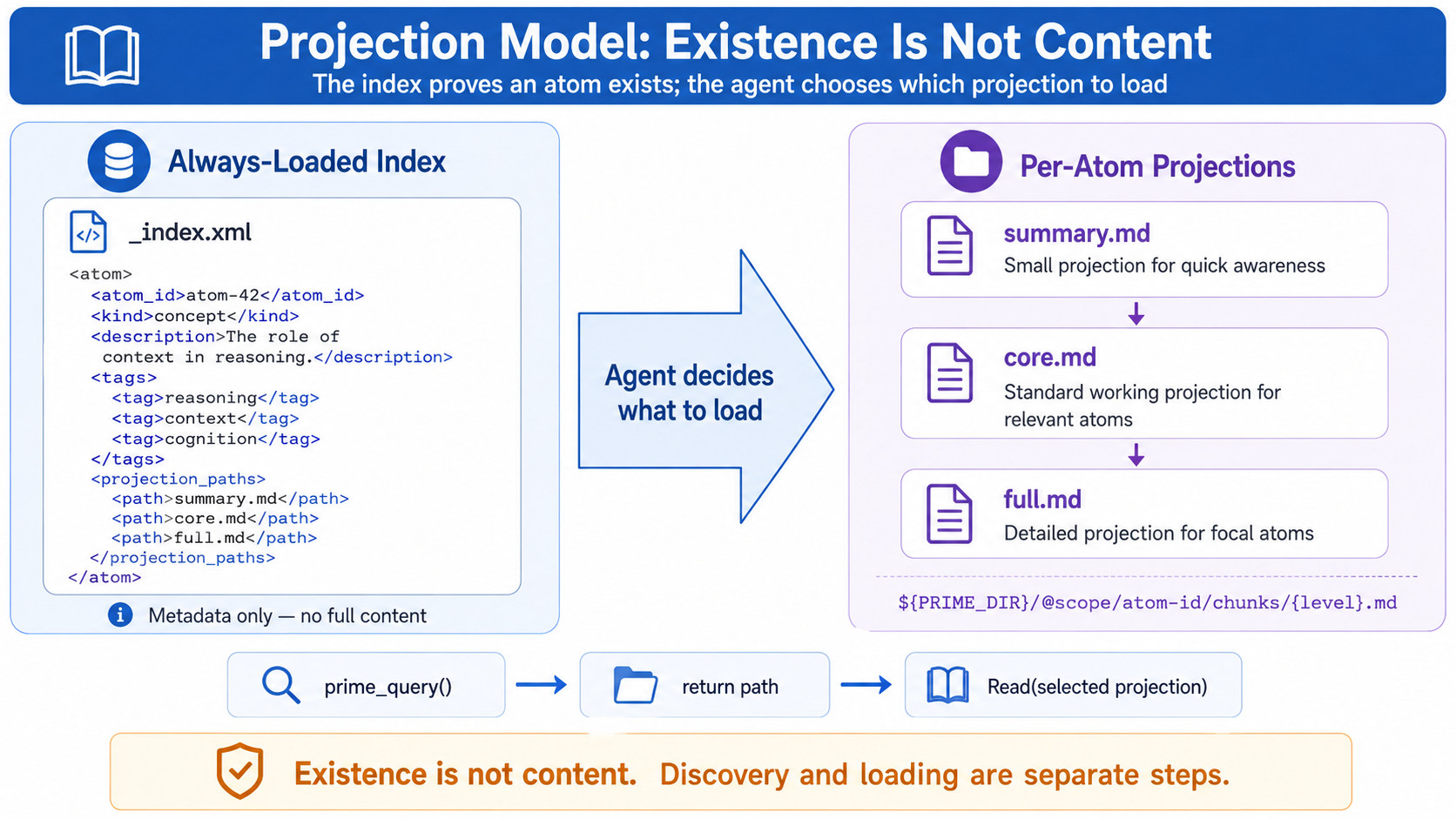
The mechanism that lets an agent decide how much of an atom to load. Three levels, kind-aware splitting, deterministic chunker.
The three levels
| Level | Token budget | Loaded when | Contains |
|---|---|---|---|
summary | ~30 tok | Always — already in _index.xml | description + tags + 1-line claim |
core | ~150 tok | Retrieved as adjacent / supporting | + key body fields (claim, applies-to, severity) |
full | ~380 tok | Retrieved as direct hit / focal atom | + sources, examples, remediation, exceptions |
The agent picks level per query via the MCP tool:
prime_query({
scope: "focus:input-validation",
level: "core", // ← summary | core | full
tags: ["api-endpoint"],
budget_tokens: 800,
})
The chunker is kind-aware
What goes in summary depends on the kind. A rule's
summary is its claim; a method's summary is its goal; a
fact's summary is its statement. The chunker
(packages/compiler/src/chunker.ts) walks the AST per-atom:
// packages/compiler/src/chunker.ts (signature)
export interface ChunkLevels {
/** ~30 tok: description + tags + 1-line claim */
summary: string;
/** ~150 tok: + core body fields */
core: string;
/** ~380 tok: + sources + examples + relations + notes */
full: string;
}
export function chunk(atom: AtomDeclaration): ChunkLevels { ... }Per-kind splitting rules
| Kind | summary | core | full |
|---|---|---|---|
rule | The claim | + applies-to, severity | + remediation, exceptions, validates-with |
pattern | Problem statement | + solution + structure | + examples, behaviours |
fact | Statement | + confidence + applies-to | + sources, counter-conditions |
method | Goal | + key steps | + contract, tools, examples |
persona | Posture | + voice + style hooks | + examples, anti-patterns |
Compiled artifact layout
compiled/
└── @scope/
└── kind-name/
├── atom.yaml # metadata only
├── graph.yaml # resolved edges
└── chunks/
├── summary.md # ~30 tok
├── core.md # ~150 tok
└── full.md # ~380 tok
The runtime never reads chunks/. The MCP server returns paths; the
agent reads them via its own Read tool.
Why exactly three levels?
Two is too few — agents need a "summary in the index" + "core for retrieval-hits" + "full for focal atoms." Four is unnecessary — the third tier already handles everything that doesn't fit in core. Empirically (~12 corpora compiled across the reference and example Primes) the three-level split has not needed extension.